[Emacs] Org-Drill: 个人单词本
简介
最近开始准备英语的终身学习,开始物色背单词软件,第一个想到的是 Anki 。虽然安装了,但是在 Arch Linux 官网中关于 Anki 的 wiki 提到了另一个同类项目 org-drill[1], 我马上点开,很快啊。秉持着“ALL IN ONE”的理念,马上在 Emacs 上配置来试用,感觉还不错。
Org-Drill 是 Ord mode 的一个扩展,是一个基于分布复习算法的记背应用,简单说就是用来背东西的。
个人的 GitLab 项目地址:https://gitlab.com/phillord/org-drill/.
Fork 到 GitHub 的仓库地址:https://github.com/louietan/org-drill.
文档就在项目里边,写得还是比较详细。
安装配置
可以通过 MELPA 安装,直接 M-x package-install RET org-drill RET, 或者克隆仓库到本地。
简单配置:
(require 'org-drill)
(require 'org-drill-anki)
;;; config
(setq org-drill-maximum-items-per-session 40
org-drill-maximum-duration 30 ; 30 minutes
;; org-drill-scope 'directory
)
(defalias 'destructuring-bind 'cl-destructuring-bind)
我在使用过程中会发现它报找不到 destructuring-bind 函数的错,然后发现这个函数现在加了个前缀 cl-destructuring-bind, 所以写一个昵称。
使用
它提供了多种卡片的类型,有普通型、填空型、双面型等,当然也支持自定义。因为是我用来背单词的,只需要用普通型的就好,有需要的可以参考文档的配置。
卡片内容
卡片是写在一个 .org 文件内:
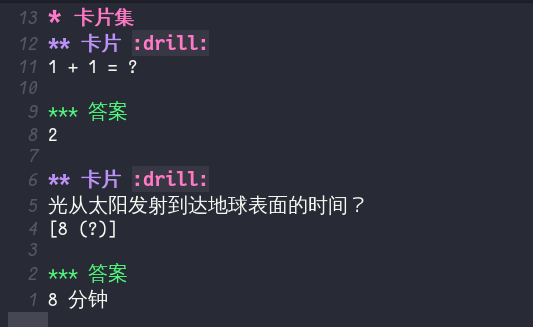
一个带有 drill 标签的标题就是一张卡片,它的第一个标题就是答案。问题和答案的标题无所谓,其文本是标题下的文本。
如何开始
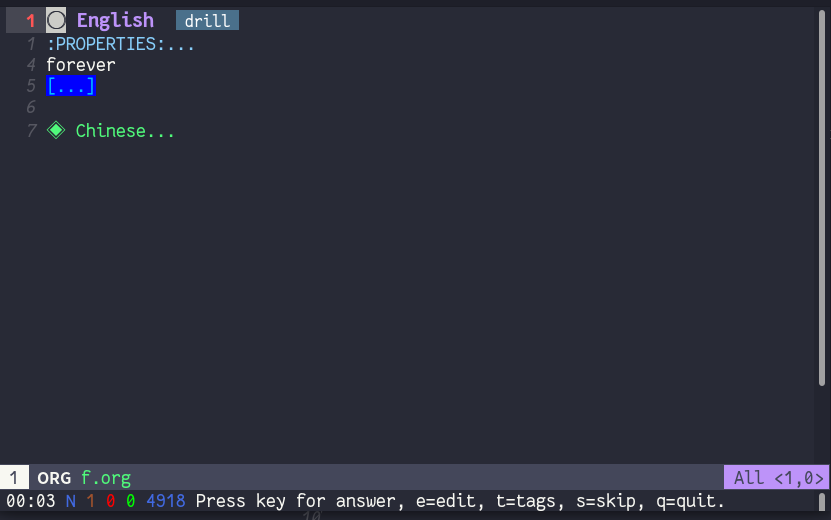
在当前 buffer 下,执行 org-drill (M-x org-drill RET) 。它首先会读取数据,然后进入到 drill session.
其他的标题都会被收起来,只留下一个打了 drill 的标签(也就是要背的)。问题的文本会展示: forever 和它的音标 -–— 这里音标被隐藏了,估计是因为我用了中括号。
按下任意键,答案就会显示。这时你会被询问记忆情况,从 0-5 打分。按下之后会记录到 .org 文件中,接着是下一张卡片。
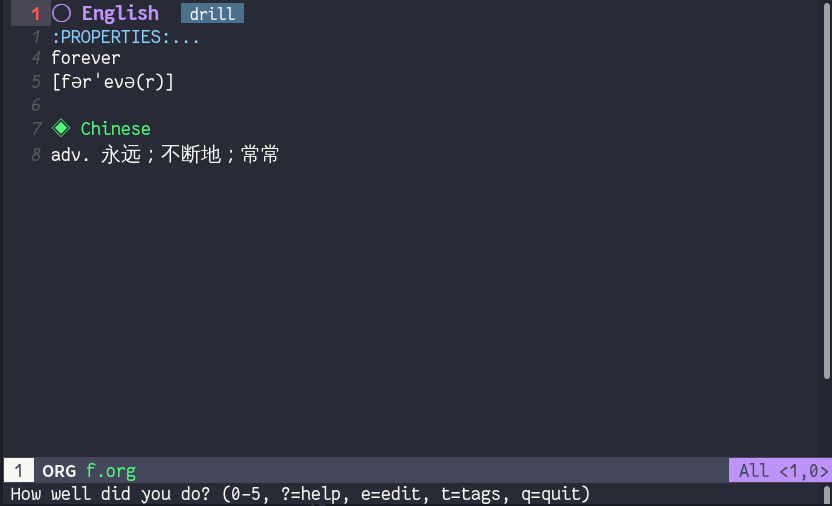
可以使用的按键:
?查看分数的标准(按q返回)t改当前卡片的标签,然后继续学习q暂停学习,可通过org-drill-resume继续学习e跳转的标题处,可以编辑标题,此时已经退出学习模式了,可通过org-drill-resume继续学习
各个分数标准为:
- 0 完全忘记
- 1 看到答案后还是要想一会儿(其他的比背单词更抽象的记忆会用的)
- 2 看到答案后就想起了
- 3 花了一小会儿还是想起来了
- 4 稍加思索就想起来
- 5 立刻记起
其中,0-2 分表示你已经记不到了,接下来还会碰到; 3-5 分表示你记住了,会安排在几天之后复习。
读入卡片
org-drill 通过一个变量 org-drill-scope 用来指定哪些文件里的内容使用,它的值都是符号(可以是列表),根据文档它有以下类型:
file当前 buffer 的内容,忽略隐藏项目。默认tree当前光标的子树file-no-restriction当前 buffer ,不论是否为隐藏file-with-archives当前 buffer ,且与其有关联的归档文件agenda所有 agenda 的文件agenda-with-archives所有 agenda 的且关联的改好文件directory与当前文件所在目录下的所有.org文件(file1 file2 …)文件名列表,列出的文件都会被扫描
任务量
(setq org-drill-maximum-items-per-session 40
org-drill-maximum-duration 30)
每次学习的任务量最多不超过 40 张卡片,学习时长最多不超过 30 分钟。
个人单词库制作
单词库
我在网上找了一堆,最后找到了一个词汇列表的项目: GitHub - jnoodle/English-Vocabulary-Word-List: Common English Vocabulary Word List, 它里面提供了单词列表,就是纯单词,没有音标也没有翻译。
根据另一个大佬的大佬的词典项目:GitHub - skywind3000/ECDICT: Free English to Chinese Dictionary Database, 给单词列表优化,加上音标和翻译。
把两个项目都克隆下来,需要用到的分别是单词列表 Oxford 3000.txt, Oxford 5000.txt 和词典工具 stardict.py 以及词库(7z 压缩包)。
首先合并单词列表,3000 是基础, 5000 是扩展:
cat 'Oxford 3000.txt' 'Oxford 5000.txt' > Oxfort.txt
写一个 Python 脚本,用来读取单词列表,在词库中查询它的翻译:
from stardict import DictCsv
import os
dict_file = os.path.expanduser("~/pyfile/ecdict.csv")
sdict = DictCsv(dict_file)
with open(os.path.expanduser("~/pyfile/Oxford.txt")) as f:
lst = f.readlines()
lst = [each.replace("\n", "") for each in lst]
# 将文件分成 26 个,a.org, b.org, ...
for n in range(97,123):
char = chr(n)
filename = os.path.expanduser("~/drill/%s.org" % char)
with open(filename, "w") as f:
f.write("#+startup: overview\n* English Words: %s\n\n" % char.capitalize())
for word in filter(lambda w: w[0] == char, lst):
data = sdict.query(word)
if not data:
continue
content = "** English :drill:\n" + word +"\n"
if data["phonetic"]:
content += "/%s/" % data["phonetic"] + "\n"
content += "\n"
content += "*** Chinese\n"
content += data["translation"]
content += "\n\n"
f.write(content)
如果怕词库不够大,去拿这个:https://github.com/skywind3000/ECDICT-ultimate/releases/tag/1.0.0, 修改相应的代码。
在 Emacs 中配置:
(setq org-drill-scope
(directory-files "~/drill/english-words/" t "[^.]"))
大文件
如果把所有单词都放到一个 .org 文件的话,学习时会非常卡,加载下一张卡片需要很长时间。根据文档建议,把大文件化小,放到一个目录下。这样时间花销就只有初始化的数据加载。
后记
目前暂时不考虑诸如记忆效率参数的调整,也仅用于背单词,如果后续用上了再更新。